ML Last Term Notes
1. CNN Backpropagation
Extending gradient descent to update kernels and weights in a convolutional architecture. Gradients propagate through pooling and convolutional layers via the chain rule.
1.a Forward Pass Recap
| Layer | Equation / Description |
|---|---|
| Convolution | — linear operation between input and kernel |
| Detector | — non-linearity zeroing negative activations |
| Pooling | Max/Average pooling for dimensionality reduction and regularization |
| Fully Connected | — final classification layer |
1.b Backward Mechanism
Update FC Weights (W)
Update Kernel (K)
Gradient propagates backward through Pooling → Activation (ReLU) → Kernel.
Max Pooling Backprop Gradient passes only to the max-value unit from the forward pass; all others receive zero gradient.
Parameter Count (Weight Sharing)
Weight sharing makes CNNs far more parameter-efficient than FFNNs on the same input size.
2. Recurrent Neural Networks (RNN)
A class of neural networks for sequential data where the order of inputs is crucial. RNNs maintain a hidden state that carries information across timesteps.
2.a Motivation: IID Breakdown & Sequential Data
Standard supervised learning assumes data samples are Independent and Identically Distributed (i.i.d.). Sequential data violates this — in language, time-series, or sensor readings each observation depends on previous ones. A vanilla FFNN has no mechanism to share context across positions, and requires fixed-size input.
RNN Solution A recurrent connection feeds the hidden state back into the computation at step , encoding the sequence history into a running “memory” vector.
2.b Sequence Modeling Types
| Type | Description | Example |
|---|---|---|
| One-to-One | Standard FFNN — single input → single output, no sequence | — |
| Many-to-One | Sequence input → single output | Sentiment analysis, time-series forecasting |
| One-to-Many | Single input → sequence output | Image captioning |
| Many-to-Many (Sync) | Input & output same length | POS tagging, NER, frame labeling |
| Many-to-Many (Delayed) | Encoder-Decoder: output starts after full input consumed | Machine translation |
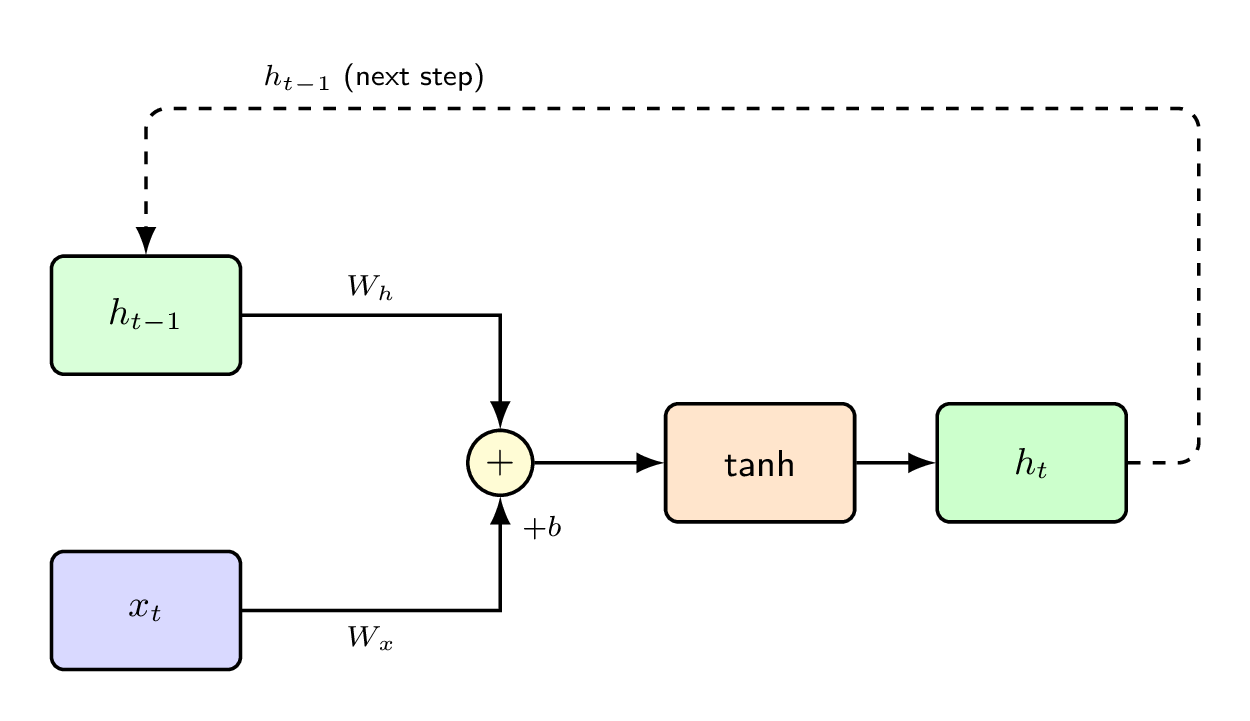
2.c Architecture & Forward Equations
Where:
- : input→hidden, : hidden→hidden (recurrent), : hidden→output
- : typically — : softmax (classification) or linear (regression)
2.d Multi-Layer RNN & Parameter Sharing
RNN cells can be stacked: the hidden state of layer becomes the input of layer . In Keras, intermediate layers require return_sequences=True. The defining property is parameter sharing — the same are used at every timestep, enabling variable-length inputs and efficient parameter use.
3. LSTM & Vanishing Gradient
LSTM was designed to solve the vanishing gradient problem in standard RNNs by maintaining a separate cell state — a gradient highway regulated by learnable gates.
3.a Vanishing Gradient Problem
During BPTT, gradients are multiplied repeatedly by and . For long sequences this product approaches zero exponentially — the network cannot learn long-range dependencies. The cell state in LSTM keeps this product near 1 when the forget gate is open.
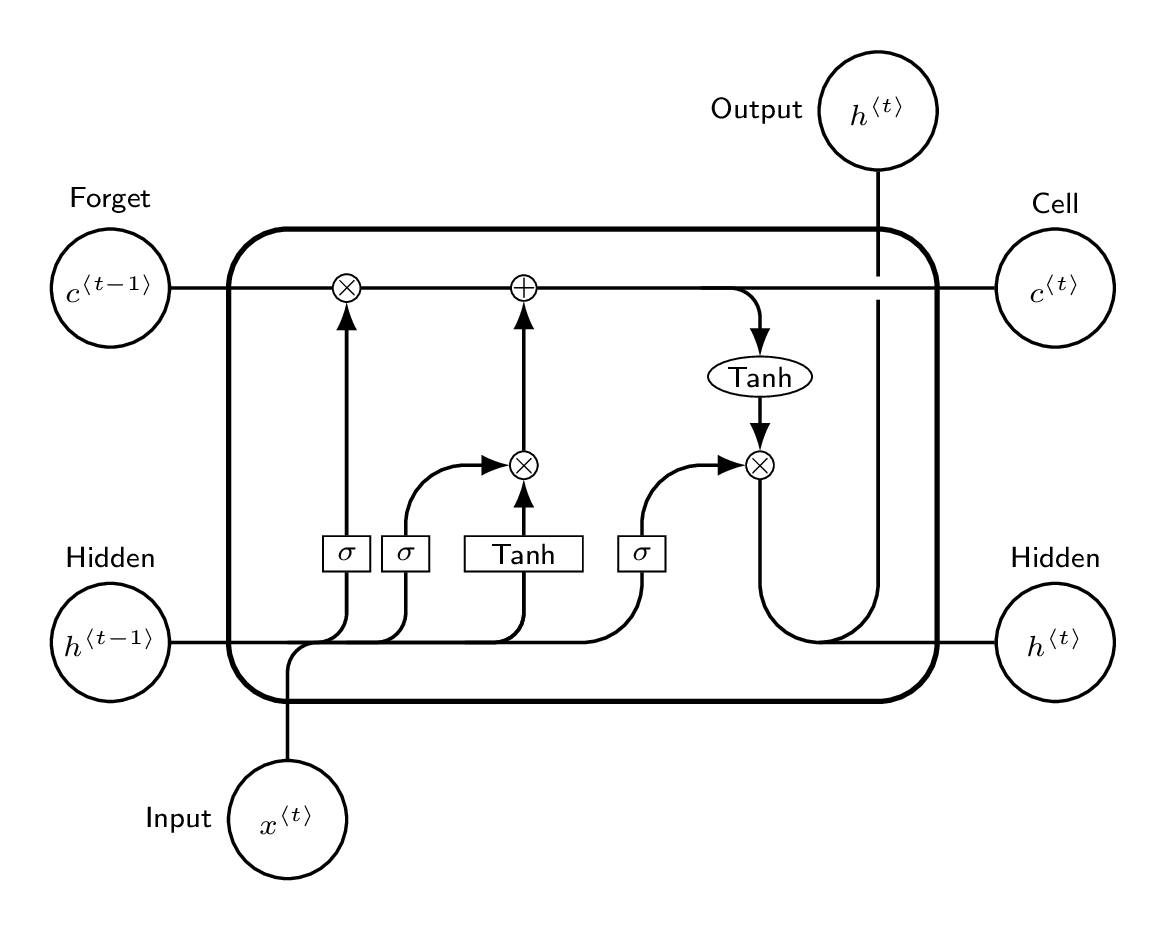
3.b Gate Equations
All gates receive concatenated input :
State Updates:
= element-wise multiplication. keeps old cell state; forgets it.
| Gate | Role |
|---|---|
| Forget | output 0 = forget old memory; 1 = keep entirely |
| Input | Controls how much of the candidate is written to cell state |
| Candidate | Proposed new values for cell state via of concatenated input |
| Output | Filters what fraction of is exposed as hidden state |
3.c Parameter Counting
Each gate has weight matrix shape plus bias , where = input dim, = LSTM units:
= input dim, = LSTM units, = output classes. Factor 4 = four gates (f, i, c̃, o).
4. Attention Mechanism
Attention was introduced to overcome the information bottleneck of a fixed-length context vector in vanilla Encoder-Decoder networks. The decoder now dynamically focuses on different encoder positions at each decoding step.
4.a Encoder-Decoder Without Attention
The vanilla seq2seq model compresses the entire input sequence into a single fixed vector . The decoder generates output from only this vector. For long sequences, this bottleneck causes severe information loss.
Bottleneck Problem For a 50-word sentence, all information must fit into one fixed-size vector. Empirically, translation quality degrades sharply as input length grows.
4.b Bahdanau (Additive) Attention
At each decoder step , a different context vector is computed as a weighted sum over all encoder hidden states :
: previous decoder hidden state — : encoder state at position — : learned alignment params. Score computed before decoder step (uses ).
Alignment Matrix Visualizing all values reveals which source positions each output token attends to — giving interpretable word alignments in translation tasks.
4.c Luong (Multiplicative) Attention
Luong et al. compute the alignment score after the decoder step, using the current hidden state :
| Bahdanau | Luong | |
|---|---|---|
| Hidden state used | (pre-step) | (post-step) |
| Formula type | Additive | Multiplicative |
| Context scope | Many-to-one or many-to-many | Same |

5. Self-Attention & Transformer
The Transformer (Vaswani et al. 2017) replaces recurrent cells with self-attention layers entirely, enabling fully parallel computation and direct long-range dependency modeling.
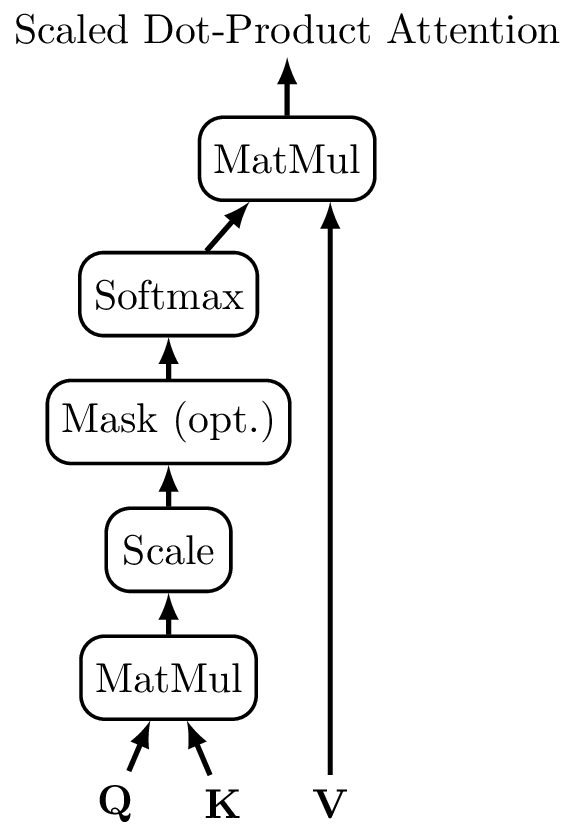
5.a Q / K / V Self-Attention
For input sequence , three linear projections create Query, Key, and Value vectors per position:
Scaled Dot-Product Self-Attention:
Division by prevents dot-products from growing large and saturating softmax. Each position receives a weighted sum of all value vectors.
5.b Transformer vs RNN Encoder-Decoder
| RNN | Transformer | |
|---|---|---|
| Processing | Sequential: depends on | All positions in parallel |
| Dependency path | steps between distant positions | via self-attention |
| Positional info | Implicit in recurrent order | Explicit positional encoding (sinusoidal or learned) |
| Multi-head | — | independent heads; concatenate outputs |
Why This Matters In an RNN, information from step 1 must survive transformations to reach step . In a Transformer, every pair of positions attends to each other directly in a single layer — drastically reducing the path length for long-range information.
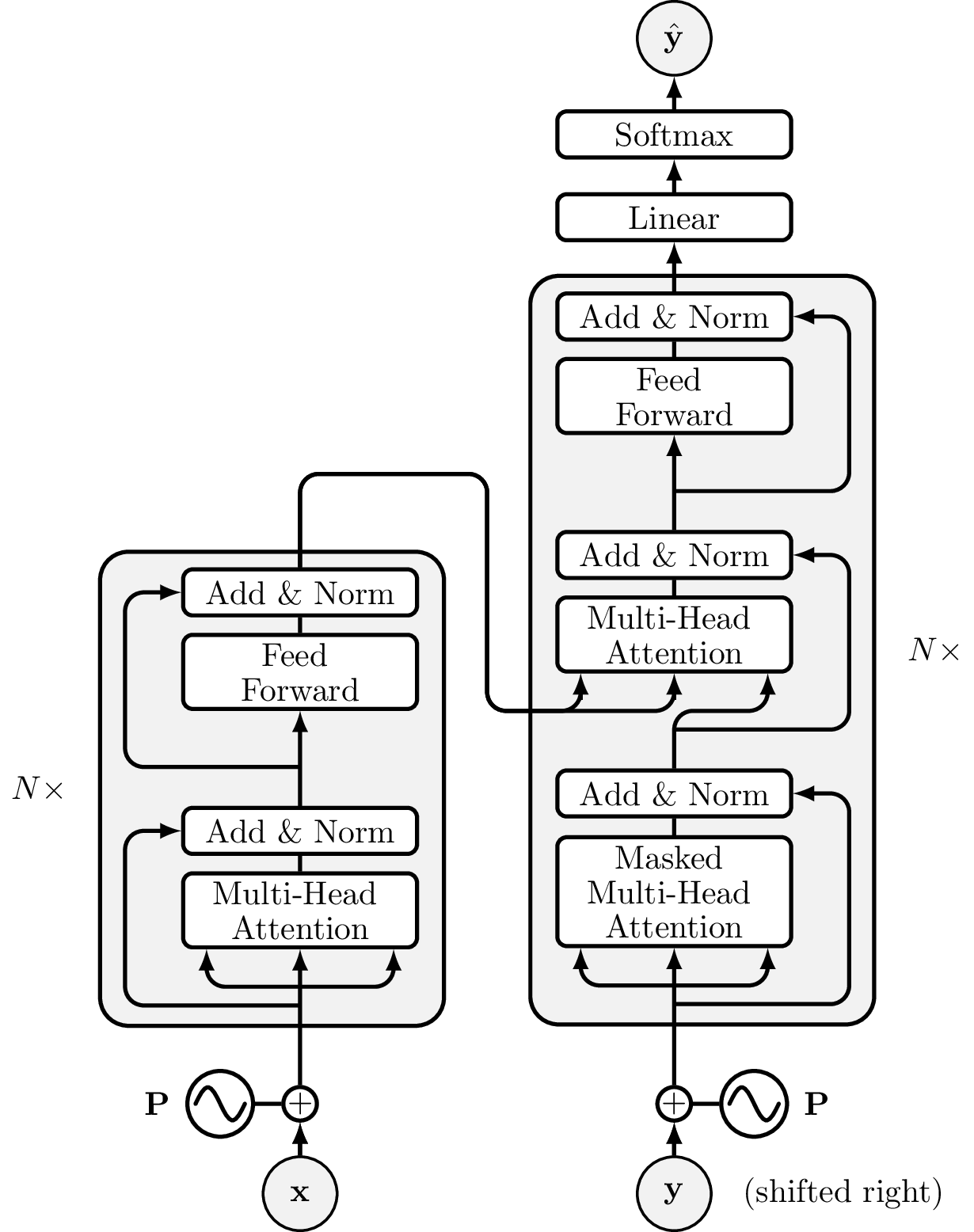
6. Backpropagation Through Time (BPTT)
BPTT trains recurrent networks by unrolling them into a deep feed-forward network (with shared weights), then applying standard backpropagation.
6.a BPTT Procedure
- Forward — Compute all and for the full sequence.
- Loss — Compute total loss (e.g., cross-entropy at each output step).
- Backward — Compute by accumulating gradients across all timesteps (shared weights).
- Update — Apply accumulated gradients via SGD / Adam to the shared weight matrices.
Truncated BPTT Backpropagation is limited to steps back for very long sequences. Reduces memory and computation at the cost of not learning ultra-long-range dependencies.
7. Reinforcement Learning
RL is a paradigm where an agent learns a policy through interaction with an environment, using reward signals as the only feedback. No labeled examples — the agent discovers good behavior via trial and error.
7.a RL vs Supervised Learning
| Supervised Learning | Reinforcement Learning | |
|---|---|---|
| Input | Labeled pairs | No labels; reward |
| Feedback timing | Immediate, correct answer given | Delayed; reward may come much later |
| Actions affect future? | No | Yes — actions influence future states |
| Goal | Minimize prediction error | Maximize cumulative reward |
Reward Hypothesis All goals can be described as maximizing the expected cumulative reward. Central hypothesis of RL.
7.b Agent-Environment Loop
At each timestep : agent observes , selects action , environment returns reward and next state .
Agent state is any function of the history. In fully observable environments .
7.c Return & Discounted Return
Undiscounted:
Discounted:
: only immediate reward. : all future rewards equally valued. Ensures sum converges; reflects that near-term rewards are more certain.
7.d Value Functions & Policy
| Component | Description |
|---|---|
| Policy | Agent’s behavior function — maps states to actions or distributions |
| Value Function | Expected future reward from state |
| Action-Value | Expected future reward from taking action in state |
| Model (optional) | Predicts and given — not always learned |
| Model-Free | Learns from raw experience (Q-learning, SARSA) |
| Model-Based | Builds environment model to plan ahead |
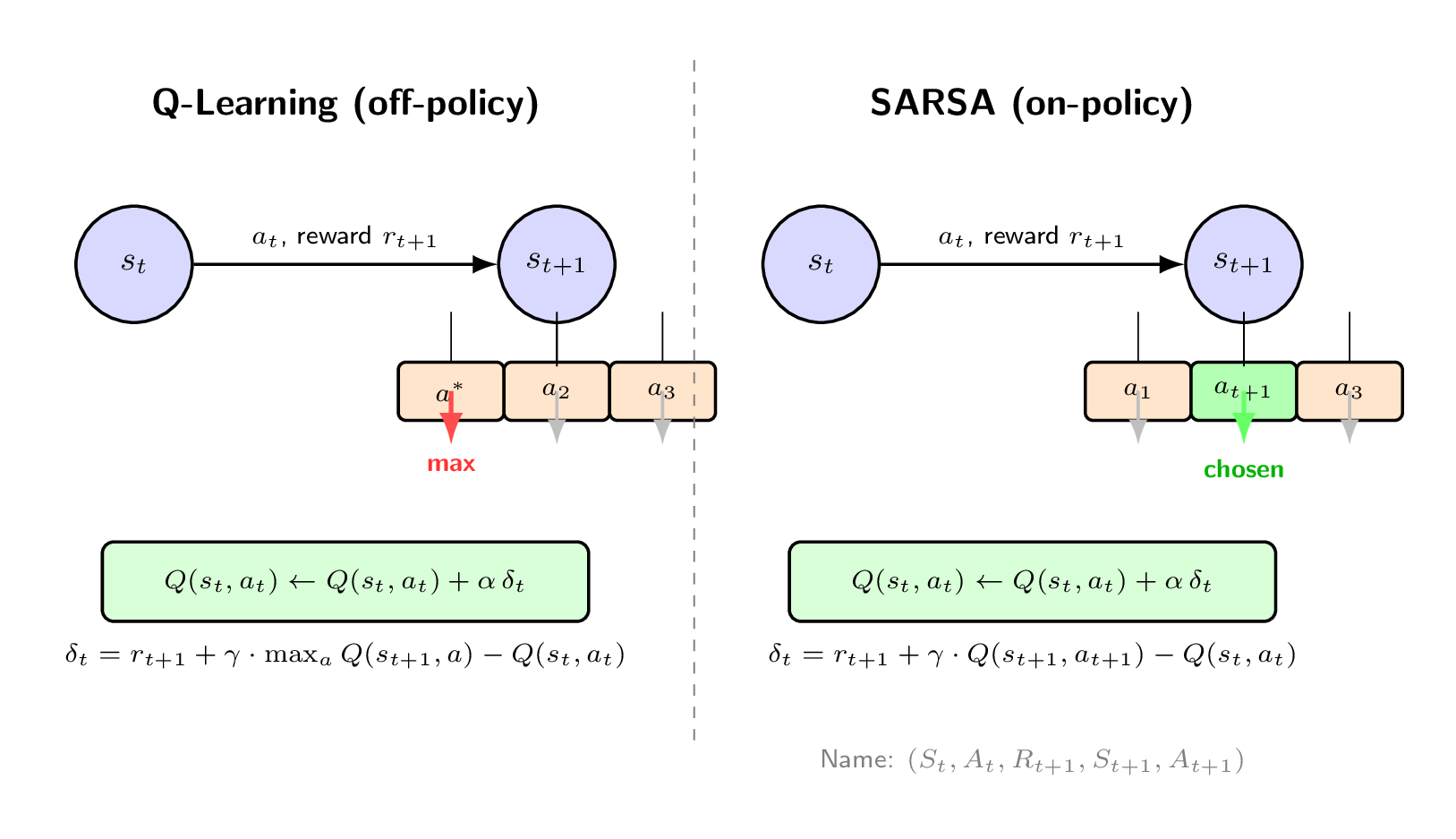
7.e Q-Learning & SARSA
Both learn an action-value function . The only difference is which next-step value is used as the bootstrap target:
Q-Learning (Off-Policy):
Bootstraps from the greedy best action in , regardless of what was actually taken. Learns optimal policy even while exploring.
SARSA (On-Policy):
Bootstraps from the value of the next action actually chosen by the current policy.
SARSA Name Origin The update uses the tuple — five elements, hence “SARSA”.
| Q-Learning | SARSA | |
|---|---|---|
| Type | Off-policy | On-policy |
| Bootstrap target | where is actually taken | |
| Behavior | Optimistic — assumes best future action | Conservative — penalizes risky explorations |
| Convergence | To regardless of exploration policy | To optimal for current exploration strategy |
| Differ when | Same condition |
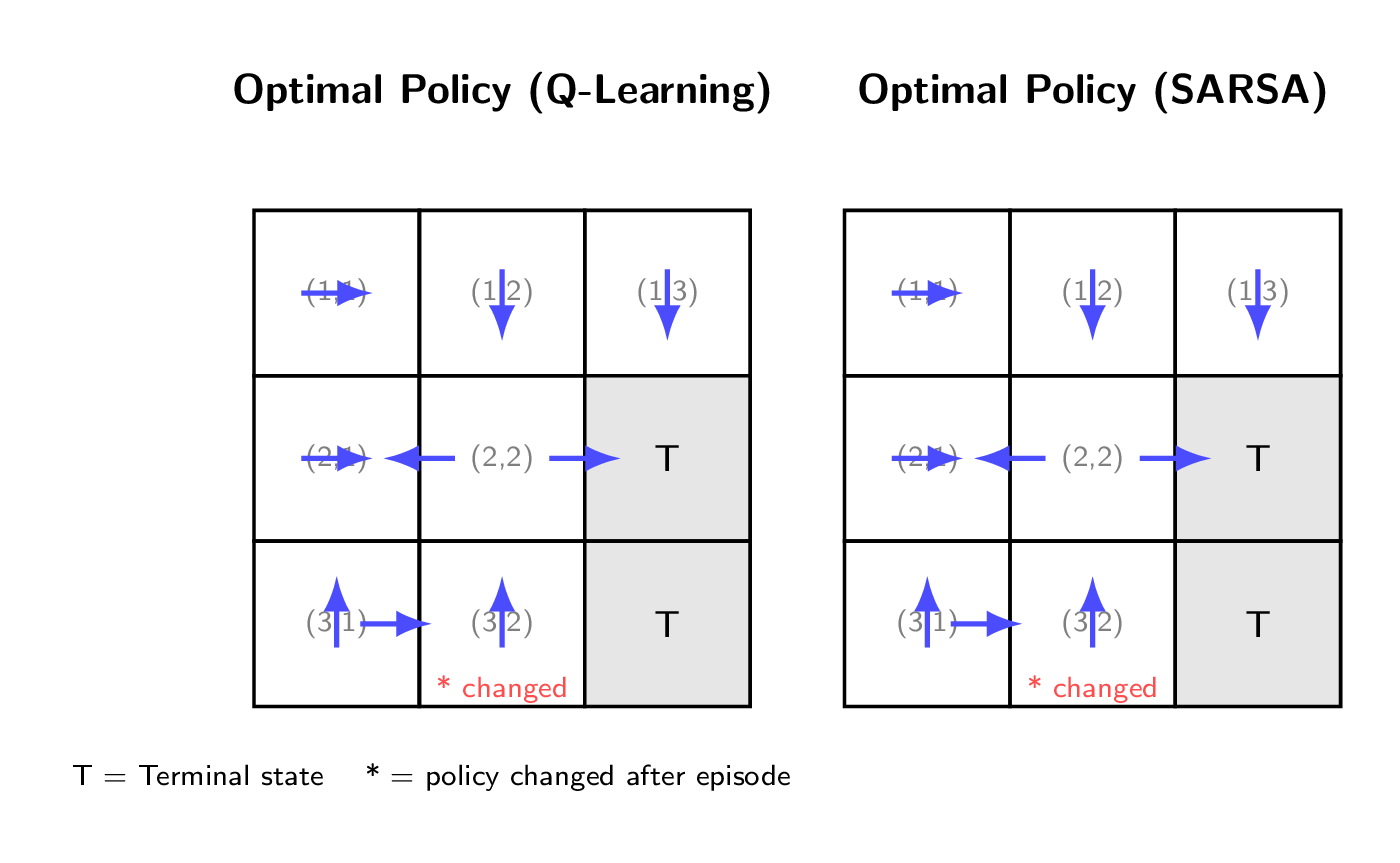
7.f Optimal Policy & Grid World
After training, selects in each state. A single episode updates only visited states — the rest remain unchanged.
Episode Example Path with . Only , , are updated. Policy at changes from ”↑ or →” to ”↑ only” because falls sharply from reward .
8. Glossary
| Term | Definition |
|---|---|
| IID | Independent & Identically Distributed — standard ML assumption violated by sequential data |
| Parameter Sharing | Same weight matrices used at every RNN timestep |
| Vanishing Gradient | Gradients shrink exponentially during BPTT; solved by LSTM cell state highway |
| Cell State | LSTM long-term memory highway — regulated by forget / input gates |
| Context Vector | — weighted sum of encoder states used by decoder |
| Alignment Score | measures relevance of encoder position to decoder step |
| Self-Attention | Computes pairwise relationships between all token pairs in parallel |
| Q / K / V | Query, Key, Value — three learned linear projections in Transformer self-attention |
| Scaled Dot-Product | |
| Return | — cumulative discounted reward from step |
| Value | — expected return from state |
| Policy | Agent’s behavior; deterministic or stochastic |
| Q-Learning | Off-policy TD: bootstraps from — converges to |
| SARSA | On-policy TD: bootstraps from where is actually taken |
| TD Error | — correction signal for both algorithms |
Goodfellow et al. (2016) · Hochreiter & Schmidhuber (1997) · Bahdanau et al. (2015) · Vaswani et al. (2017) · Sutton & Barto (2018) · IF3270 Lecture Decks 5–9 · Attention & Transformer diagrams: Fraser Love, NNTikZ (2024)