Petunjuk Soal Beri tanda O pada pilihan yang tepat, dan tanda X pada pilihan yang salah. Pilihan yang tidak diberi tanda tidak mendapat nilai.
Soal 1
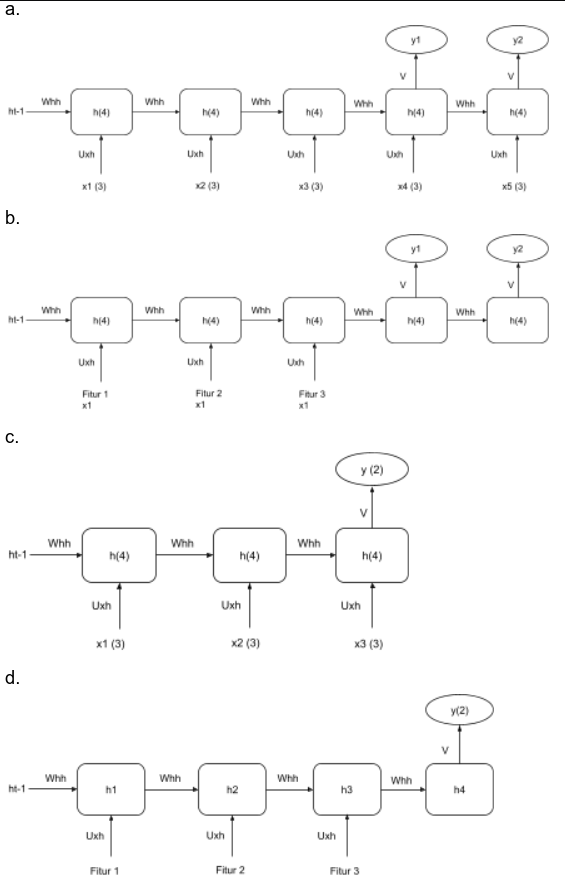
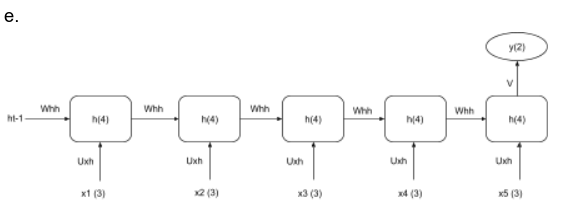
Soal: Terdapat spesifikasi arsitektur neural network “many-to-one” yang menerima input terdiri atas 3 fitur, sebuah hidden layer berupa RNN yang terdiri atas 4 neuron dengan 5 time-step, dan sebuah output layer yang terdiri atas dua neuron. Jika digambarkan dalam ‘unfolded network’ tanpa mengilustrasikan bias, maka arsitekturnya adalah sebagai berikut.
Analisis setiap pilihan (berdasarkan gambar soal):
a — 5 blok h(4), setiap blok menerima x(3), output y1 & y2 muncul dari dua timestep terakhir (t=4 dan t=5).
→ X ❌ — many-to-one seharusnya output hanya dari 1 timestep terakhir saja, bukan dua.
b — 5 blok h(4), tetapi input-nya adalah “Fitur 1 x1”, “Fitur 2 x1”, “Fitur 3 x1” (masing-masing 1 fitur per timestep berbeda), output y1 & y2 dari dua timestep terakhir.
→ X ❌ — Interpretasi fitur salah: seharusnya tiap timestep menerima vektor 3 fitur (x(3)), bukan 1 fitur per timestep. Lagi pula output dari 2 timestep.
c — Hanya 3 blokh(4), input x(3) tiap timestep, output y(2) dari timestep terakhir saja.
→ X ❌ — Jumlah timestep hanya 3, seharusnya 5.
d — 4 blok (h1, h2, h3, h4) dengan input masing-masing “Fitur 1”, “Fitur 2”, “Fitur 3” sebagai 3 timestep terpisah, output y(2) dari timestep terakhir.
→ X ❌ — 3 fitur diinterpretasikan sebagai 3 timestep (bukan vektor fitur dalam 1 timestep), dan hanya 4 blok hidden. Tidak sesuai.
e — 5 blokh(4), setiap blok menerima x(3) (vektor 3 fitur), output y(2)hanya dari timestep t=5 (terakhir) via bobot V.
→ O ✅ — Sesuai spesifikasi: 5 timestep, 4 neuron hidden, 3 fitur input, output hanya dari timestep terakhir = many-to-one.
Kunci InterpretasiMany-to-many equal: setiap baris = satu time-step. Tiga kolom input = 3 fitur yang diterima sekaligus pada timestep tersebut.
a.Untuk t=1, maka data inputnya adalah: ⟨0.1, 0.2, 0.3⟩.
→ O ✅ — Baris pertama, kolom x1 x2 x3.
b.Untuk t=2, maka data inputnya adalah: ⟨0.2, 0.5, 0.8⟩.
→ X ❌ — Input t=2 adalah baris kedua = ⟨0.4, 0.5, 0.6⟩. Pilihan ⟨0.2, 0.5, 0.8⟩ adalah nilai kolom x1 di t=1,2,3 dibaca ke bawah (interpretasi columnar yang salah untuk many-to-many equal).
c.Nilai neuron pertama di hidden layer t=2 adalah:tanh(0.4×0.1+0.5×0.1+0.6×0.1+0.2×x+0.1)
→ O ✅ — Input t=2 = ⟨0.4, 0.5, 0.6⟩, tiap fitur × bobot 0.1, plus kontribusi hidden sebelumnya 0.2×x, plus bias 0.1.
d.Nilai neuron pertama di hidden layer t=2 adalah:tanh(0.2×0.1+0.5×0.1+0.8×0.1+0.2×x+0.1)
→ X ❌ — Nilai 0.2 dan 0.8 adalah data kolom x1 di t=1 dan t=3, bukan input t=2 yang benar ⟨0.4, 0.5, 0.6⟩.
e.Jika nilai hidden t=2 adalah z=[z1,z2], nilai output t=2 adalah:sigmoid(0.3×z1+0.3×z2+0.3)
→ O ✅ — 2 hidden neuron masing-masing berbobot 0.3, bias 0.3, ke 1 neuron output.
Soal: Tentukan pernyataan yang benar mengenai Context Vector dan Encoder-Decoder.
a.Context Vector berusaha menangkap informasi dari hidden unit timestep terakhir pada Encoder, jadi kita tidak bisa memanfaatkannya pada arsitektur “one-to-many”.
→ X ❌ — Benar bahwa context vector berasal dari hidden state terakhir encoder, namun tidak benar bahwa ia tidak bisa dipakai untuk one-to-many. Context vector bisa menjadi initial hidden state decoder untuk berbagai konfigurasi arsitektur.
b.Context Vector hasil dari tahap encoder hanya digunakan oleh bagian Decoder timestep pertama saja.
→ X ❌ — Pada arsitektur standar (tanpa attention), context vector c=hNx digunakan sebagai initial hidden state s0 decoder dan biasanya juga disertakan sebagai input di setiap timestep decoder, bukan hanya timestep pertama.
c.Dalam arsitektur Encoder-Decoder, tidak ada input dari dataset pelatihan yang menjadi masukan untuk tahap Decoder.
→ X ❌ — Selama training (dengan teacher forcing), output target dari data pelatihan (yt−1) digunakan sebagai input decoder timestep berikutnya.
d.Dalam arsitektur Encoder-Decoder “many-to-many” di mana panjang input mungkin berbeda dengan panjang output, output dari timestep sebelumnya menjadi masukan untuk Decoder.
→ O ✅ — Inilah mekanisme decoder autoregresif: st=f(st−1,yt−1,c) dan yt=g(st).
e.Salah satu contoh pemanfaatan Encoder-Decoder dengan arsitektur “many-to-one” adalah menerima masukan berupa video dan menghasilkan teks kalimat penjelasannya (video captioning).
→ X ❌ — Video captioning menghasilkan kalimat = sequence token, bukan satu nilai. Arsitekturnya adalah many-to-many (encoder memproses sequence frame video, decoder menghasilkan sequence kata). Bukan many-to-one.
Pilihan
Jawaban
a
X
b
X
c
X
d
O
e
X
Soal 5
Soal: Model estimasi jumlah penumpang 1 bulan berikutnya berdasarkan time series 10 tahun, menggunakan RNN dengan data 3 bulan sebelumnya.
a.Arsitektur one-to-many tidak dapat digunakan.
→ O ✅ — Input adalah sequence 3 nilai (3 bulan sebelumnya) → arsitektur many-to-one yang tepat. One-to-many mengasumsikan input tunggal, tidak cocok.
b.Output layer dari model RNN ini memiliki satu neuron, sesuai untuk task regresi.
→ O ✅ — Prediksi jumlah penumpang (nilai kontinu) = regresi → 1 neuron output, aktivasi linear.
c.Jumlah timestep dari model RNN ini adalah 10.
→ X ❌ — Jumlah timestep = panjang input sequence = 3 (3 bulan sebelumnya). Data 10 tahun = ukuran dataset, bukan timestep.
d.Output akhir model berupa sequence 3 nilai.
→ X ❌ — Output adalah 1 nilai (prediksi 1 bulan berikutnya).
Pilihan
Jawaban
a
O
b
O
c
X
d
X
Soal 6
Soal: Mesin penerjemah (machine translation): teks bahasa sumber → teks bahasa target, dikembangkan dengan RNN.
a.Arsitektur one-to-many atau many-to-one tidak dapat digunakan.
→ O ✅ — Machine translation memerlukan many-to-many (seq2seq) karena baik input maupun output adalah sequence.
b.Output layer dari model RNN memiliki jumlah neuron sebanyak jumlah vocabulary unik bahasa sumber dari data latih.
→ X ❌ — Output layer berukuran vocabulary bahasa target, karena model memprediksi token dalam bahasa target.
c.Karena panjang input ≠ panjang output, model RNN tersebut dirancang untuk melakukan task sequence labeling.
→ X ❌ — Sequence labeling = input dan output sama panjang (misal NER). Machine translation adalah seq2seq / sequence generation, bukan sequence labeling.
d.Karena panjang input ≠ panjang output, diperlukan arsitektur many-to-many dengan output akhir berupa sequence vocabulary sesuai indeks nilai dari output layer setiap timestep.
→ O ✅ — Encoder-Decoder many-to-many; decoder menghasilkan distribusi softmax atas vocabulary di tiap timestep, dan token dipilih via argmax.
Pilihan
Jawaban
a
O
b
X
c
X
d
O
Soal 7
Soal: Model analisis sentimen teks (positif/negatif) dengan RNN.
a.Arsitektur many-to-one tidak dapat digunakan.
→ X ❌ — Justru many-to-one adalah arsitektur yang paling sesuai: banyak token → 1 label sentimen.
b.Output layer dari model RNN memiliki dua neuron sigmoid.
→ X ❌ — Untuk klasifikasi biner standar, cukup 1 neuron sigmoid. Dua neuron sigmoid bukan pendekatan yang umum (yang umum adalah 2 neuron + softmax, atau 1 sigmoid).
c.Model RNN ini termasuk melakukan task regresi.
→ X ❌ — Analisis sentimen adalah klasifikasi, bukan regresi.
d.Output akhir dari model diambil dari output layer timestep terakhir.
→ O ✅ — Pada many-to-one, hanya hidden state timestep terakhir yang diumpankan ke output layer.
Pilihan
Jawaban
a
X
b
X
c
X
d
O
Soal 8
Soal: Perbedaan memori antara RNN dan FFNN.
a.FFNN dapat menyimpan konteks waktu jika jumlah layer cukup banyak.
→ X ❌ — Menambah layer FFNN tidak memberikan kemampuan memori temporal; FFNN tidak punya recurrent connection.
b.RNN mampu mempelajari hubungan temporal dalam data.
→ O ✅ — Hidden state ht membawa informasi dari timestep sebelumnya.
c.FFNN hanya mampu memetakan input ke output tanpa mengingat input sebelumnya.
→ O ✅ — FFNN bersifat stateless; setiap forward pass independen.
d.RNN dapat menyimpan informasi jangka pendek atau panjang tergantung arsitekturnya.
→ O ✅ — Simple RNN: short-term memory (vanishing gradient). LSTM/GRU: long-term memory.
Pilihan
Jawaban
a
X
b
O
c
O
d
O
Soal 9
Soal: Bidirectional RNN (Bi-RNN) vs RNN untuk ukuran arsitektur yang setara.
a.Bi-RNN menghasilkan keluaran pada output layer sejumlah dua kali keluaran RNN.
→ X ❌ — Jumlah output layer tidak berubah; yang berbeda adalah representasi hidden (digabung dari 2 arah), bukan ukuran output layer.
b.Bi-RNN memerlukan jumlah time step setengah kali lipat jumlah time step RNN.
→ X ❌ — Jumlah timestep sama; Bi-RNN memproses sequence yang sama, dua kali (forward + backward).
c.RNN dan Bi-RNN keduanya memproses data masukan dari masa lalu ke masa depan.
→ X ❌ — RNN hanya forward. Bi-RNN memproses dua arah: forward (kiri→kanan) dan backward (kanan→kiri).
d.Bi-RNN memiliki jumlah parameter lebih banyak daripada RNN.
→ O ✅ — Bi-RNN = 2 RNN (forward + backward) → parameternya ~2× RNN dengan ukuran setara.
Pilihan
Jawaban
a
X
b
X
c
X
d
O
Soal 10
Soal: Pernyataan yang benar mengenai Bi-RNN.
a.Bi-RNN hanya cocok untuk data teks.
→ X ❌ — Bi-RNN dapat digunakan untuk semua data sekuensial: audio, time series, sinyal biologis, dll.
b.Hasil dari dua arah forward state dan backward state pada Bi-RNN digabungkan dengan cara penjumlahan.
→ X ❌ — Penggabungan yang paling umum adalah concatenation[ht→;ht←], bukan penjumlahan.
c.Bi-RNN banyak digunakan pada persoalan sequence tagging, seperti sentiment analysis.
→ O ✅ — Sequence tagging (NER, POS tagging, dll.) adalah use case utama Bi-RNN karena butuh konteks dari dua arah.
d.Bi-RNN mengabaikan urutan data masukan.
→ X ❌ — Bi-RNN justru sangat bergantung urutan; ia memproses sequence secara berurutan dari dua arah.
Pilihan
Jawaban
a
X
b
X
c
O
d
X
Soal 11
Soal: Dalam sequence labeling dengan LSTM, bagaimana cara umum mengonversi output hidden state menjadi label kelas?
a. Dengan membandingkan hidden state dengan semua input
b. Dengan menggunakan softmax layer setelah hidden state ✅
c. Dengan menghitung rata-rata semua hidden state
d. Dengan fungsi aktivasi sigmoid di input
Jawaban: b ✅
Pada setiap timestep t, hidden state ht diproyeksikan ke dimensi jumlah kelas:
y^t=softmax(V⋅ht+by)
a. Banyaknya token yang diprediksi benar adalah dua token. → X ❌ (hanya 1)
b. Akurasi hasil prediksi adalah 100%. → X ❌
c. Prediksi kelas akhir untuk input sequence tersebut adalah [B, C, A]. → O ✅
d. Semua jawaban salah → X ❌ (karena c benar)
Pilihan
Jawaban
a
X
b
X
c
O
d
X
Bagian II — LSTM Forward & Backward Pass (Nilai 20)
Setup Soal
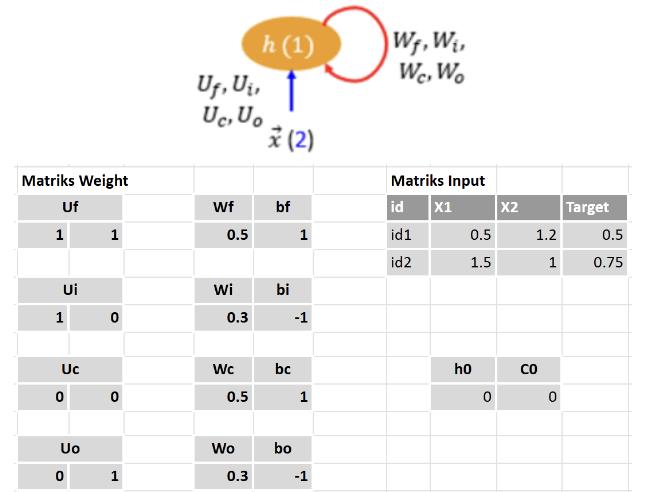
Soal: LSTM sederhana, 1 hidden neuron (h∈R1), input 2 fitur (x∈R2). Target adalah nilai pada hidden unit.
Gradient ke gate output o2:∂o2∂L=∂h2∂L⋅tanh(c2)=(−0.416)(0.653)=−0.272δo2=∂o2∂L⋅o2(1−o2)=(−0.272)(0.512)(1−0.512)=(−0.272)(0.512)(0.488)=−0.068
Gradient ke cell state c2:∂c2∂L=∂h2∂L⋅o2⋅(1−tanh2(c2))=(−0.416)(0.512)(1−0.6532)=(−0.416)(0.512)(0.574)=−0.122
Gradient ke candidate c~2:∂c~2∂L=∂c2∂L⋅i2=(−0.122)(0.633)=−0.077δc~2=∂c~2∂L⋅(1−c~22)=(−0.077)(1−0.7922)=(−0.077)(0.373)=−0.029
Gradient ke input gate i2:∂i2∂L=∂c2∂L⋅c~2=(−0.122)(0.792)=−0.097δi2=∂i2∂L⋅i2(1−i2)=(−0.097)(0.633)(1−0.633)=(−0.097)(0.633)(0.367)=−0.022
Gradient ke forget gate f2:∂f2∂L=∂c2∂L⋅c1=(−0.122)(0.288)=−0.035δf2=∂f2∂L⋅f2(1−f2)=(−0.035)(0.973)(1−0.973)=(−0.035)(0.973)(0.027)=−0.001
Gradient weight dari t=2 (bobot W terhubung ke ht−1=h1=0.154; bobot U ke x2; bias ke 1):
Total gradient ke h1 (dari L1 langsung + backprop dari t=2 melalui recurrent connection):
Dari L1 langsung:
∂h1∂L1=h1−h^1=0.154−0.500=−0.346
Dari t=2, gradient mengalir balik ke h1 melalui semua gate di t=2 yang bergantung pada h1:
∂h1∂L2=Wf⋅δf2+Wi⋅δi2+Wc⋅δc~2+Wo⋅δo2=(0.5)(−0.001)+(0.3)(−0.022)+(0.5)(−0.029)+(0.3)(−0.068)=−0.000+(−0.007)+(−0.014)+(−0.020)=−0.042
Total:
∂h1∂L=−0.346+(−0.042)=−0.388
Gradient ke gate output o1:∂o1∂L=∂h1∂L⋅tanh(c1)=(−0.388)(0.280)=−0.109δo1=(−0.109)⋅o1(1−o1)=(−0.109)(0.550)(0.450)=−0.027
Gradient ke cell state c1 (dari h1 langsung + dari c2=f2⋅c1+…):
∂c1∂Ldari h1=∂h1∂L⋅o1⋅(1−tanh2(c1))=(−0.388)(0.550)(1−0.2802)=(−0.388)(0.550)(0.922)=−0.197
Notasi Koordinat pada Soal Soal menulis posisi ruang sebagai (a,b)=(baris,kolom), dihitung mulai dari (1,1) di pojok kiri-bawah (tempat agen start) — bukan(x,y)=(kolom,baris) seperti pada grid di atas. Dengan notasi soal ini, posisi-posisi pada gambar konsisten dengan teks soal:
Wumpus = baris 3 kolom 1 → ditulis soal sebagai (3,1) → pada grid (x,y) di atas = (x=1,y=3)
Gold = baris 3 kolom 2 → ditulis soal sebagai (3,2) → pada grid (x,y) = (x=2,y=3) — sel yang sama juga memuat Breeze & Stench, sesuai gambar
Pit = baris 1 kolom 3 → ditulis soal sebagai (1,3) → pada grid (x,y) = (x=3,y=1) (dua pit lain yang terlihat pada gambar berada di (x=3,y=3) dan (x=4,y=4))
Karena episode pada soal juga memakai notasi (baris,kolom) yang sama, semua state akhir episode di bawah ini cocok dengan jenis terminal-nya tanpa konversi tambahan.
Terminal states (notasi soal, baris-kolom): Wumpus di (3,1), Gold di (3,2), Pit di (1,3), (3,3), dan (4,4).
Reward:
Transisi normal (non-terminal): R=0
Menuju Gold: R=+10
Menuju Wumpus atau Pit: R=−10
State terminal: Q-value = 0
Parameter:α=0.4, γ=0.6, inisialisasi semua Q(s,a)=0
Pemetaan State Soal → Grid (x,y)
State (a,b) pada soal (baris, kolom) terletak di sel grid (x=b,y=a). Jadi Q((2,1),⋅)→(x=1,y=2), Q((1,2),⋅)→(x=2,y=1), Q((2,2),⋅)→(x=2,y=2) — semuanya berdekatan dengan START di (x=1,y=1), sesuai jalur eksplorasi tiga episode.
Interpretasi Setelah 3 episode, Q-learning baru belajar dari 3 jalur yang dieksplor. State yang belum dikunjungi (semua Q=0) belum memiliki preferensi aksi. Hanya 3 state yang mendapat update bermakna:
(2,1): Hindari E (menuju Wumpus, Q=-4)
(1,2): Hindari N (menuju Pit, Q=-4); E adalah arah menuju (2,2) yang dari sana bisa ke Gold
(2,2):E adalah aksi terbaik jelas (Q=+4), menuju Gold